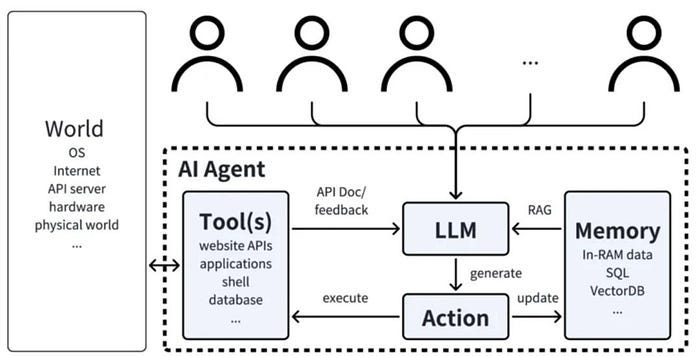
The 5 Phases of LLM Agents: Research Insights, Applications, and Future Development
The operation of LLM agents follows key phases, including perception, reasoning, decision-making, execution, and feedback.

First look at Agent
Previous AI models mainly rely on input instructions to let the model execute step by step and finally complete the task. Agent, on the other hand, does not need to rely on clear instructions, but thinks based on the goal, plans, executes, reflects and other processes to achieve the set goal. In fact, it is like when humans deal with complex problems, they first analyze the problem and answer the problem based on the analytical thinking. In this process, humans may also use tools such as books and search engines to get the answer in the end, and then calculate the result.
With the development of LLM technology, generative AI models also have the ability to think for themselves, and can also access real-time information and perform real-world tasks through tools. This AI system that combines reasoning, logic and external information access capabilities is called
Agent (intelligent agent), and its capabilities go beyond the independent operation mode of a single AI model.

Let’s take another simple example. Suppose you are planning a trip and you need to know the weather and flight information of your destination and book a hotel. If you use an AI model alone, it can only provide suggestions based on existing training data and may not be able to provide real-time and accurate information. But if this AI model is equipped with a weather API, flight query tool, and hotel reservation system, it can obtain the latest weather conditions in real time, query the best flights, and help you complete the reservation directly. This AI system can be understood as an intelligent agent.
Agent Definition
Recently, everyone has been talking about Agent, such as AutoAgent, Dify, Manus, etc. Suddenly, a question came to my mind. What is an Agent? Is there a clear definition? For this reason, I searched the Internet for the definition of Agent. It is said that the earliest word “Agent” can be traced back to the ancient Roman period, and it can also be found in the philosophical works of some philosophers.
An article said that the philosophical concept of Agent refers to a concept or entity with autonomy. It can be a man-made object, a plant or an animal, and of course a person. This definition is good, and I have no objection. Interested friends can search for this definition to understand it. After sorting out the story line, you can organize a paper. Personally, I think that if something can respond to the external environment and correct its own behavior, it can be an intelligent agent.
In terms of the application of artificial intelligence, there are currently two main types of agents (excluding small tool agents):
One is an agent based on a small model + rules, which uses the model to perform intent classification, entity recognition, sentiment classification, etc., and then manually adds process control and fixed external call interfaces to allow the agent to give corresponding answers at different process nodes. For example, the intelligent customer service used by most companies currently generally uses an intent classification model for menu navigation at the first level. Each business corresponds to a business process node, and each node is manually configured. Through entity recognition and intent recognition, it enters the next node and finally realizes business processing or introduction. Although each company talks about the accuracy of intelligent customer service, how many problems it has solved, and how much manpower it has saved, for actual users, it is still manual convenience.
One is an agent based on a large model + rules, Since the large model (LLM) has relevant capabilities such as logical reasoning, task planning, and tool calling, it is equivalent to integrating the entity recognition, intent classification, manual process orchestration, and interface external call functions of the small model. To this end, the current mainstream AI Agent is based on a large model. The Agent can autonomously perceive, plan, execute and feedback to complete complex tasks. For example, the recent Manus has attracted everyone’s attention. Compared with traditional AI, which is limited to passive response, Agent emphasizes autonomous decision-making and task execution capabilities. (The future development direction will basically rely on the ability of large models~)
However, no matter where the Agent first came from, how do you understand the Agent? Let’s refer to a white paper on Agent released by Google last year, which gives the definition of Agent: Agent is a software system that can make autonomous decisions and take actions. It can observe the environment, use tools, and perform tasks in a goal-oriented manner. Agent has the following key features:
- Autonomy: Can run without human intervention and make decisions independently.
- Goal-driven: Possessing initiative, even without explicit instructions, it will reason about how to complete the task.
- Environmental perception: Able to process external inputs, such as user requests, sensor data, or database information.
- Scalability: Can integrate different tools (API, database, computing module, etc.) to improve execution capabilities.
- Adaptability: Able to adjust behavior according to task requirements and optimize execution paths.
Since the breakthrough of LLM, the technical community has never stopped exploring agents. In the past two or three years, we have witnessed the emergence of various agent showcases, each of which has triggered heated discussions. Everyone passionately believes that the agent singularity has arrived, but later they will be disappointed and feel that it is still far from being implemented. The two voices will always coexist, which is also in line with the law of technological development.
Five Phases of agent development
Phase 1: Tool-based Agent Frameworks
Tool-based agent frameworks appeared at the same time as ChatGPT came out. At that time, LLM had just demonstrated its powerful text generation capabilities, but its application was still limited to pure text environments, and prompt engineering was initially developed. In order to realize the basic connection mechanism between language models and external tools, developers adopted predefined tool sets, simple decision trees, and basic memory management to achieve limited autonomy. Representative works include: LangChain, BabyAGI, and early versions of AutoGPT.
Limitations: LLM is confined in a “cage”, heavily relying on manually defined tools and processes, and has low flexibility.
Phase 2: Cognitive Agents
The development of cognitive agents is accompanied by the emergence of more powerful language models such as GPT-4. The key drivers of this stage include: the reasoning, planning and reflection capabilities of the new generation of LLMs are beginning to emerge, Chain-of-Thought technology has made initial breakthroughs, enabling the model to display detailed reasoning processes. Developers use appropriately designed prompts and feedback loops to allow LLMs to show preliminary language models that can show preliminary planning capabilities, reflection mechanisms, internal thinking processes and self-correction. Typical representative works of this period include ReAct framework, Reflexion system, Inner Monologue agent.
Limitations: Limited environmental interaction capabilities, mainly operating at the thinking level, limited reasoning depth, there are still “wandering” and logical breaks in complex reasoning chains, unstable self-correction capabilities make it difficult to maintain long-term goals, easy to deviate from the original goals in extended tasks.
Phase 3: Environment-Interacting Agents
The development of environment-interacting agents began in mid-2023. The key technology drivers of this period include breakthroughs in multimodal models, GPT-4V allows agents to “see” the environment, browser automation technology provides a standardized interface for interacting with the network environment, and developers begin to try to let agents do some tasks such as interface understanding, environment navigation, and execution of complex operation sequences. Representative works of this period include AutoGPT Advanced Edition, BrowserGPT, Adept ACT-1, Open Interpreter, etc.
Limitations: Usually focus on specific areas and lack cross-domain integration capabilities.
Phase 4: Autonomous Multimodal Agents
The development of autonomous agents began in early 2024. The key drivers of this stage include the popularization of large multimodal models, breakthroughs in long context windows, support for context window lengths of hundreds of thousands or even millions of tokens, and the maturity of agent development tools and platforms. Developers began to explore truly autonomous agent systems that can achieve advanced planning architectures, dynamic environment adaptation, long-term goal maintenance, and adaptive learning. Representative works of this period include Devin, OpenHands, etc.
Limitations: high resource consumption, stability and consistency challenges.
Phase 5: End-to-End General Agents
After releasing Deep Research, the OpenAI team mentioned in an interview that Deep Research is an enhanced and fine-tuned version of the o3 model, and it is an end-to-end agent. After o1, the large model industry has fully entered the era of reasoning models. The basic model capabilities continue to improve. More and more powerful basic models have internalized more capabilities. Agents can plan and execute completely autonomously without the support of a special framework. They can continuously learn and improve themselves, and can set and adjust goals autonomously. It will eventually become the practical application form of AGI.
Components of an Agent
In 2023, Lilian Weng, former head of applied research at OpenAI, proposed the definition of an agent and its four core elements in her blog post. Now it is 2025, and AI is developing rapidly. The four elements have all changed a lot. Let’s take a look.
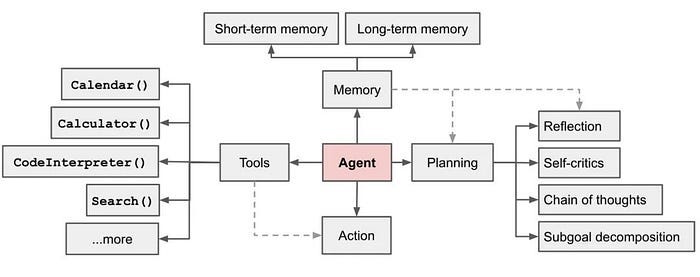
Agent consists of multiple components working together to achieve efficient decision-making and task execution. Many articles mention that:
LLM Agent consists of four key parts: planning, memory, tools and actions, which are responsible for task decomposition and strategy evaluation, information storage and recall, environmental perception and decision assistance, and converting thinking into actual actions. But in fact, the main key parts of the current LLM Agent are: dynamic reasoning planning of the base LLM, tool module, and memory module. As shown in the figure below:
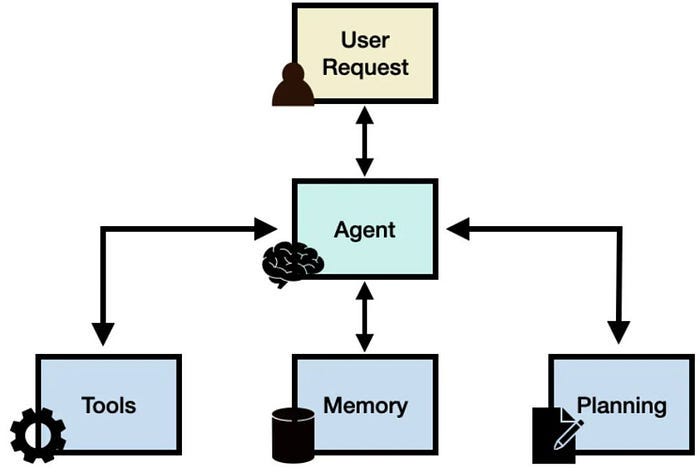
1. Planning
Planning is currently the fastest-growing capability among the four elements. The breakthroughs in o1 and R1 allow the large language model to demonstrate an endogenous Chain-of-Thought capability, which can generate multi-step processes for complex tasks without relying on prompt engineering and templates, as well as manually written rules or limited decision trees.
Future technology evolution direction:
- Adaptive and dynamic planning: In the future, agents will evolve in the direction of being able to automatically replan in real time according to changes in the environment and tasks, and have the ability to self-correct and dynamically adjust strategies.
- Hierarchical Planning: Construct a multi-level planning structure, integrate micro-decision-making and macro-planning, and achieve global and local collaborative optimization.
2. Memory
The research on memory of large models mainly focuses on RAG and long context window technology. Long context has made significant progress in the past two or three years. However, compared with the urgent needs of high-level capabilities such as multimodality, agent and reasoning, the current window length is still far from enough. Otherwise, large models will not be stretched in solving long logical chain deep reasoning and video generation consistency. It can be seen that the investment of major model manufacturers in the field of memory will continue to increase.
At the same time, some startups focusing on memory middleware have also appeared in the market, such as Mem0 and Letta, trying to provide some solutions for solving long-term memory. In the future, we still need to solve the problems of long-term memory embedding and persistence, dynamic memory management and intelligent retrieval, and multimodal memory integration. The best path is still to solve them through model internalization.
3. Tool use & Action
The current agent system usually pre-integrates a set of tools or APIs, which can call specific external services according to task requirements to complete tasks such as search, data query, translation, etc., and cannot dynamically select and flexibly combine tools according to task requirements.
The test set that measures the model’s ability to understand user intent and call tools to execute commands is called TAU-bench, which is a benchmark for evaluating the performance and reliability of AI Agents in real-world scenarios. TAU-bench has designed two domain scenarios: TAU-bench (Airline), which simulates users’ operations such as flight inquiries, reservations, ticket changes, ticket refunds, and airport services in aviation business scenarios, and TAU-bench (Retail), which simulates shopping consultations, product recommendations, order modifications, returns and exchanges in retail scenarios. Currently, Claude 3.7, the most powerful agent, has a problem-solving rate of 81% in the retail field, but only 58% in the aviation field. Some cases in the aviation field involve a lot of inquiries, matching flight information, amount calculations, and baggage/payment/return operations, which are still very difficult. In addition, this test set also defines a pass^k indicator, which is the probability of multiple stable passes. It can be seen that the stability of each model is not very good, so it is not expected that it can stably understand the intention and take correct actions in complex scenarios and multiple rounds of interactions. This is the current situation.
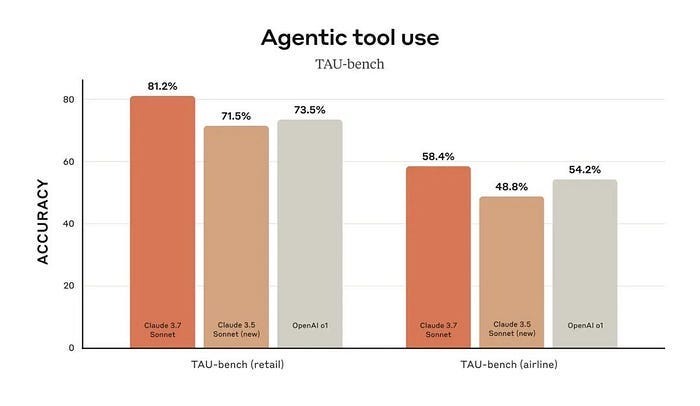
Among the four elements of an agent, the development of tool use and take action capabilities does lag behind the other two elements. It is easier to develop a model’s brain, but it is more difficult to grow hands and feet. The order of ability development of large models is opposite to that of humans. After we are born, we first develop our bodies, learn to walk, learn to operate with our hands, then learn to read and learn knowledge, and then develop high-level logical thinking ability. Models first learn knowledge, then develop thinking ability, then learn computer use, and finally embody the physical world.
Future direction of technological evolution: From the current point of view, the tool use and take action capabilities of the model are discrete and independent calls, that is, task decision-making and specific execution are often separate processes. Only OpenAI Deep Research makes continuous dynamic decisions. It will adjust the next search direction in real time according to each search result. It searches and thinks, thinks and searches, and constantly approaches the goal until the problem is solved. This is the benefit brought by end-to-end RL. Furthermore, we hope that the model will be able to adjust its action strategy in real time according to environmental feedback in the future, be able to autonomously learn and iterate tool calls, and even discover and integrate new external tool interfaces.
Agent workflow
Based on the above components of Agent, a typical Agent operation process generally includes several processes such as perception, reasoning, decision-making, execution, and feedback. Among them:
Perception: mainly receives input information, which can be user input or information obtained in the environment through sensors;
Reasoning: mainly integrates context, environmental perception information, etc., analyzes input data and plans task execution steps;
Decision Making: selects appropriate tools or operations based on the results obtained by reasoning;
Action Execution: calls API, database or computing module to complete the task;
Feedback & Learning: analyzes execution results and optimizes future decisions.
For example: in the scenario of e-commerce intelligent customer service, there is an AI intelligent customer service agent to answer customer questions. When the user input is: “Please help me check the inventory of this product.” After receiving the input information, the Agent will first correctly parse the user request through the context, and then call the inventory database API to query the data, that is, query the order information through the order number, obtain the product ID, and then obtain the inventory through the product ID; finally, combine the user question and the database result to generate a reply to the customer; output to the user: “There are currently 15 pieces of this product in stock and can be shipped immediately.”
By integrating language models, tools and intelligent orchestration, the Agent can dynamically respond to different types of user needs and achieve more powerful automation and intelligent services.
A. LLM dynamic reasoning planning
As the core decision engine of the Agent, it determines how the Agent analyzes information, accurately decomposes tasks, dynamically reason, makes choices, and executes. In this process, various prompt frameworks, multi-agent collaboration, model fine-tuning and other methods are usually used to improve the LLM reasoning planning ability. (This is an important research direction in academic research)
1. LLM capabilities in Agent
As the intelligent core of the Agent system, the large language model plays an irreplaceable central role. It mainly needs to have the following capabilities:
1) Understanding and analysis, The large model, with its deep understanding and analysis capabilities, extracts real user needs from vague or indirect expressions, supplements the information that the user does not clearly state but is necessary for task execution, and judges the difficulty of the problem and the required resources. When the information is incomplete, it requests clarification or makes reasonable assumptions. When the user says “help me check the flight to Shanghai tomorrow”, the large model can automatically recognize that the flight search tool needs to be used, and understands the need to determine key parameters such as departure point, date and preference.
2) Planning and decision making, This capability enables the Agent to handle complex multi-step tasks, that is, to decompose complex goals into manageable subtasks, design tool call sequences, and dynamically adjust the execution plan based on intermediate results. In the process, it can also evaluate the efficiency and cost of different solutions, predict possible failure points and prepare alternative solutions, and finally determine the best order for task execution. Some reasoning methods such as thinking chain, ToT, ReAct are generally used here. When executing a complex request such as “create a market analysis report for my startup project”, the LLM will plan a series of steps such as searching market data, analyzing competitors, generating charts, and writing analysis.
3) Tool call planning, Accurately map task requirements to appropriate application tools, build structured parameters that meet the tool API requirements, determine when to call tools and when to use their own knowledge, identify scenarios that require multiple tools to work together, find alternatives when the preferred tool is not available, and generate precise call instructions that meet the requirements of specific tools. For example, for the request “analyze this set of data and create visualizations”, the LLM can determine that the data processing tool needs to be used first, then the statistical analysis tool, and finally the visualization tool, and generate appropriate parameters for each tool.
4) Contextual integration, The contextual integration capability of the large model ensures the coherence and consistency of the Agent system. It tracks the task status, integrates historical interaction information, and maintains long-term memory. The extensive knowledge obtained through pre-training enables the large model to supplement professional background, apply common sense reasoning, and transfer knowledge from one field to related problems. Faced with the raw data returned by the tool, the large model provides key reprocessing capabilities, translating technical output into ordinary language, extracting core information, and integrating multi-source results into a unified answer.
5) Large model knowledge, The large model has been tempered by a huge amount of knowledge and has a huge knowledge system. It can supplement the professional knowledge that the tool may lack, apply basic world knowledge to assist decision-making, and it can also convert professional concepts into user-understandable instructions. In cross-domain scenarios, Discover the connection between different knowledge fields and apply the knowledge and experience of another field to the current scenario.
6) Explanation reprocessing, The large language model can convert complex technical output into easy-to-understand language, extract key information, reconstruct data formats, and integrate the results of multiple tools to form a unified and easy-to-understand answer. It can also compare and analyze the results of different tools and provide the most suitable visualization suggestions. For example, when a search tool returns a large amount of information, the model can extract relevant content and present it to the user in a concise way.
7) Feedback Adaptation, The large language model gives the Agent system the ability to learn and adapt. It can identify tool call failures or abnormal results, adjust strategies based on feedback, and self-evaluate the quality of the solution. The model can also monitor user satisfaction and gradually optimize the solution based on user feedback. For example, when a user is dissatisfied with the initial results, the model will understand the specific reasons and adjust the strategy, such as providing more detailed information or trying other tools.
Through these in-depth capabilities, the large model is not just a component of the Agent system, but a true intelligent core that coordinates and enhances the functionality of the entire system, making it far more than the simple superposition of the capabilities of each part.
2. Research pain points
Although large-model agents have powerful capabilities, they still face multiple technical bottlenecks.
1) In terms of reasoning ability, agents often have broken reasoning chains in complex tasks, lack of abstract thinking, and limited self-correction ability, resulting in poor performance in highly abstract fields such as scientific research. At the same time, the lack of causal reasoning ability makes it difficult to distinguish between correlation and causality, further limiting its ability to analyze complex problems.
2) In terms of tool usage efficiency, it is also a key factor restricting the development of agents. From tool selection to parameter configuration, from error handling to multi-tool collaboration, agents have obvious shortcomings in all aspects of interacting with external tools. Especially when external APIs change, agents’ ability to adapt to new interfaces is even weaker, which seriously affects their reliability and stability in practical applications.
3) In terms of long-term planning capabilities, the lack of long-term planning capabilities of large models is also a significant weakness of agents. Problems such as improper task decomposition, weak priority management, and poor plan adjustment capabilities make it difficult for agents to handle complex tasks that require long-term planning. At the same time, irrational resource allocation and non-closed feedback loops further reduce its execution efficiency, especially in dynamic environments.
4) In terms of credibility, the hallucination problem is the main obstacle affecting the credibility of the agent. The fuzzy knowledge boundary causes the model to give seemingly certain answers when it is uncertain; the fluency of language generation often conceals factual errors; context pollution and anchoring effects cause errors to be continuously amplified during the interaction process, ultimately leading to a crisis of trust in the output of the agent by users.
5) In terms of long-term memory, the context window limitation fundamentally restricts the long-term memory ability of the agent. With the extension of the interaction, the memory decay of early information, the difficulty of information retrieval, and the lack of context compression are becoming increasingly prominent, making it difficult for the agent to maintain consistency and coherence in long-term interactions, greatly limiting its application value in complex scenarios.
6) In terms of security control, ensuring the security and compliance of tool use is a research direction that cannot be ignored. This includes a permission management framework to limit the range of tools that agents can access; a certain constraint mechanism needs to be established for agent behavior to prevent dangerous operations; in the audit tracking system, the tool usage history needs to be recorded for review; at the same time, ethical decision-making models need to be considered to evaluate the ethical impact of tool use; and adversarial testing methods need to be used to discover and fix potential security vulnerabilities. Currently, some researchers are also developing formal verification technology to theoretically ensure that the agent’s tool usage behavior meets the predetermined specifications.
3. Related research
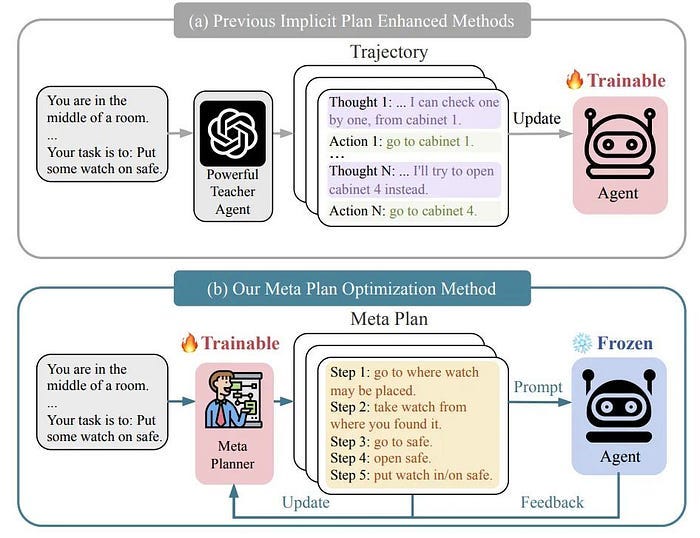
1) Peking University proposed a meta-planning optimization framework: MPO, which enhances the planning ability of LLM Agent. MPO uses meta-planning to assist agent planning and continuously optimizes meta-planning based on the feedback of agent task execution. Experiments show that MPO significantly outperforms existing baselines on two representative tasks, and analysis shows that MPO provides a plug-and-play solution, improves task completion efficiency and generalization ability in unseen scenarios.
2) Meta proposed MLGym and MLGym-bench: for evaluating and developing large model agents. Among them, MLGym is the first gym environment for machine learning (ML) tasks, which aims to promote the research of reinforcement learning (RL) algorithms in training such agents.
MLGym-bench The benchmark contains 13 open AI research tasks from different fields such as computer vision, natural language processing, reinforcement learning and game theory, providing a comprehensive platform for evaluating and improving AI research agents.
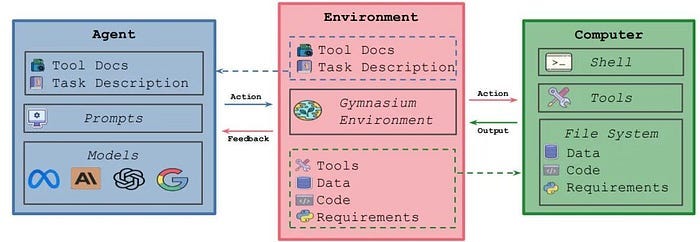
3) The University of Technology Sydney proposed ATLAS, to improve the efficiency and generalization ability of large language model (LLM) agents. ATLAS reduces the risk of overfitting and improves generalization in different environments and tasks by focusing on key steps. Experiments show that the LLM fine-tuned by key steps selected by ATLAS outperforms the LLM fine-tuned by all steps and the latest open source LLM agent.
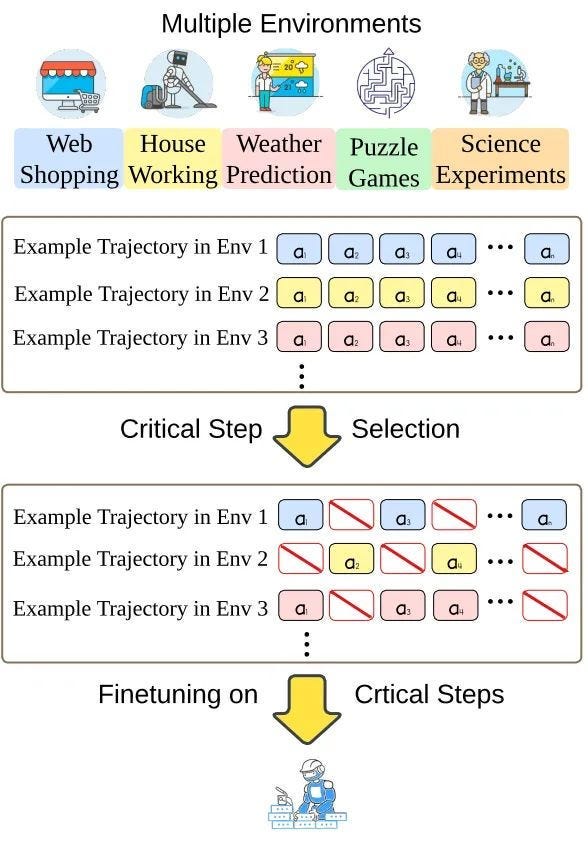
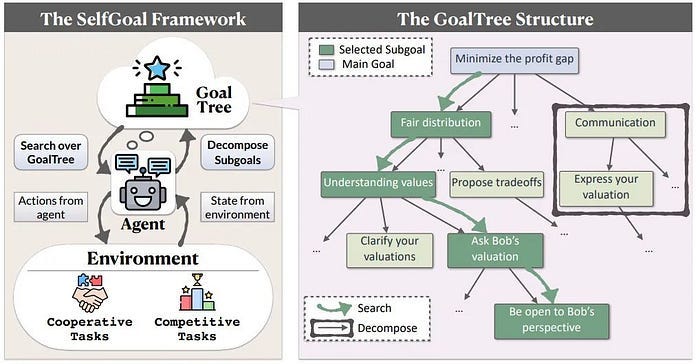
4) Fudan University proposed a large model agent automation method: SELFGOAL, which enhances the ability of large models to perform complex tasks. SELFGOAL aims to enhance the ability of large model agents to solve complex tasks under limited human priors and environmental feedback. Experimental results show that SELFGOAL significantly improves the performance of large model agents in various tasks (including competitive, cooperative, and delayed feedback environments).
B. Tools
Tools in Agent are mainly used to expand Agent’s ability to access the outside world, such as API, database, etc., so that it can perform retrieval, calculation, data storage and other operations. Note: In the case of multiple agents, other agents can also be understood as tools. It is a key direction for the development of modern AI. It significantly expands the capability boundary of the model, enabling AI to perform operations that were originally impossible to complete, such as network search, complex calculation and API call.
Through the use of tools, Agent can not only interact with the outside world in real time and obtain the latest information, but also play a professional advantage in specific fields, such as using code editors or data analysis tools to solve professional problems. This ability greatly improves the quality and accuracy of task completion, reduces hallucinations, and at the same time enhances the autonomy of AI systems and reduces the need for human intervention.
1. Tool use
1) Traditional method,Write the API code interface, let the model parse the parameters required by the code interface, and then call the interface to get the result. For example: write an interface for air ticket query. The user says: I want to buy a ticket from Beijing to Shanghai, let the model extract the two addresses of Shanghai and Beijing in the text, and then call the interface to get the result. But if you directly say: I want to buy a ticket to Shanghai, the API interface cannot be called at this time, which shows that this method has poor maintainability and scalability.
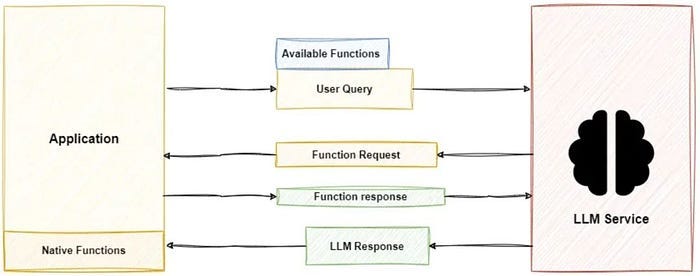
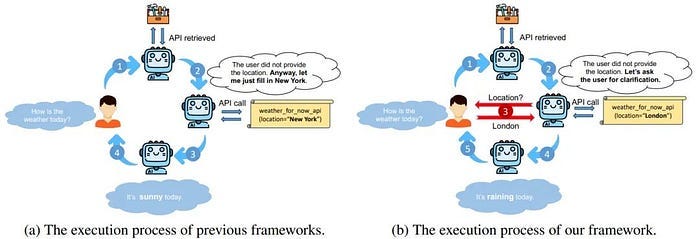
2) LLM function call, the current LLMs basically have the ability to call functions externally. After the LLM recognizes the user’s intention, it automatically selects the appropriate function from the predefined function list, generates structured JSON format parameters, and then the system executes the actual function call. This allows the model to interact with external APIs and services in a standardized way, which is the most common tool usage form in commercial APIs. The figure below is a tool application process.
3) Tool Enhanced Prompt, directly describe the available tools and how to use them in the prompt words, so that the model can generate instructions for calling the tools. This method is simple and direct, but it has high requirements for prompt engineering.
4) Tool Library, stores the tools that may be used by large models. When facing different problems, search in the toolbox and select the appropriate tool. In fact, RAG technology is just a detailed introduction to the tool API stored in the vector database. As shown in the figure below:

5) Model fine-tuning: teaching the model how to use a specific tool through specific training or fine-tuning. This method directly incorporates tool usage capabilities into model parameters, making the model perform better on specific tools.
2. Existing problems
1) Tool selection: Why use a butcher knife to kill a chicken? Develop more accurate tool selection algorithms to enable agents to make optimal decisions based on task requirements, tool functional characteristics, and historical usage results. This includes context-aware selection mechanisms that can understand the nuances of tasks; metacognitive abilities that allow agents to evaluate whether they need external tool assistance; and uncertainty-based decision frameworks to make reasonable choices when information is incomplete.
2) Tool application efficiency optimization: API interface calls are so expensive! Improving tool usage efficiency is the key to reducing resource consumption. Research focuses include streamlining tool call processes to reduce unnecessary API requests; developing tool call caching mechanisms to reuse previous call results; designing parameter optimization techniques to automatically adjust tool parameters to obtain optimal output; and establishing tool usage cost models to help agents strike a balance between efficiency and effectiveness.
3) Error handling mechanisms: Check for gaps and fill in the gaps! Using anomaly detection algorithms to identify tool call failures or abnormal outputs; failure recovery strategies to automatically try alternatives; error diagnosis systems to analyze failure causes and provide repair suggestions; and progressive retry mechanisms to adjust retry parameters based on failure modes.
4) Tool collaboration: Solving complex problems often requires multi-tool collaboration. Research includes information transfer protocols between tools to ensure seamless flow of data between tools; tool dependency management systems to coordinate tool calls with forward and backward dependencies; tool combination effect prediction models to evaluate the expected effects of different tool combinations; and tool conflict resolution mechanisms to handle conflicts or inconsistencies that may arise between multiple tools.
5) Learning tool use: Optimizing strategies from tool use successes and failures; few-shot learning techniques to quickly adapt to new tools; behavioral cloning methods to learn tool use skills from human expert demonstrations; and continuous learning architectures to continuously update tool use knowledge.
3. Related research
In 2025, Shandong University proposed TOOLRET, a heterogeneous tool retrieval benchmark containing 7.6k diverse retrieval tasks and 43k tools, which aims to evaluate the performance of large language models (LLMs) in tool retrieval tasks. In addition, the author of this article also contributed a large-scale training dataset of more than 200k instances, which significantly optimized the tool retrieval capability of the IR model;
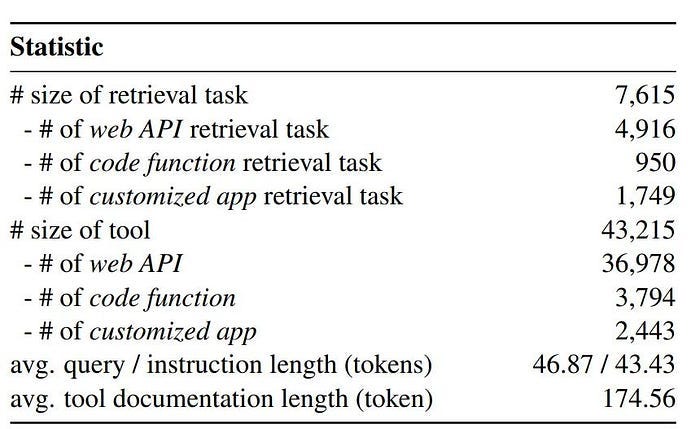
In 2025, the University of Chinese Academy of Sciences proposed a long-chain reasoning large language model that integrates external tools: START. One of its core features is to effectively stimulate the model to use external tools by inserting prompts during the reasoning process.
In 2024, the University of Hong Kong designed an automated evaluation tool, ToolEvaluator, to assess the accuracy and efficiency of LLMs in tool use;
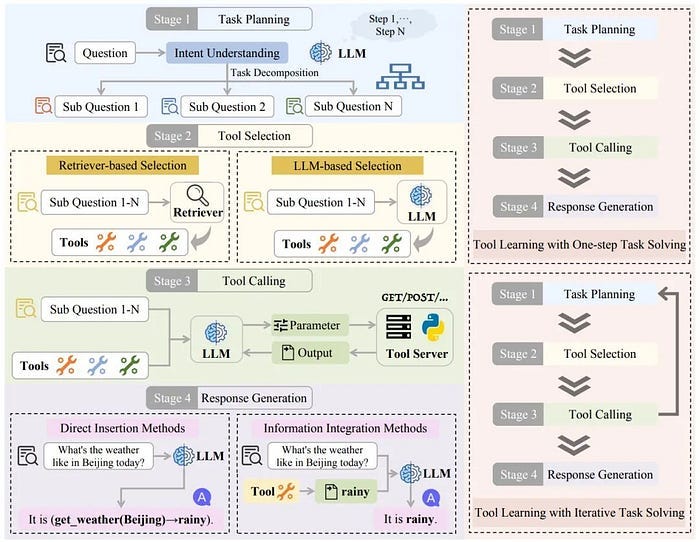
In 2024, Renmin University of China published a latest review on large model tool learning! It also provides a detailed summary of existing benchmarks and evaluation methods, and classifies them according to their relevance to different stages. To help researchers further explore this promising field.
C. Memory Module
The memory module is mainly responsible for storing and managing information, so as to achieve more accurate and personalized responses. Specifically: it not only maintains the context of the instant conversation, but also undertakes the key functions of knowledge persistence, experience accumulation and information retrieval. In the process of complex task processing, the memory module allows the agent to handle long-term dependency problems beyond the context window, while recording the tool call history and results, avoiding repeated operations and supporting result integration.
In addition, it is also responsible for tracking the progress status of multi-step tasks, ensuring the complete execution of tasks, and storing the agent’s self-evaluation history, providing basic support for metacognition and continuous improvement.
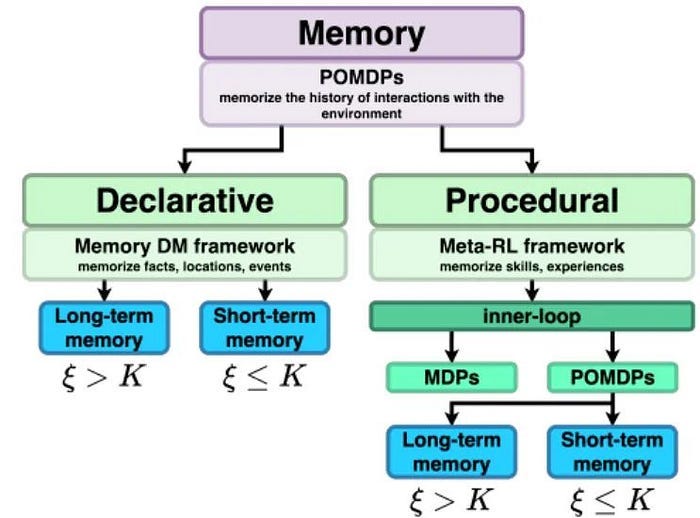
1. Long-term and short-term memory
Memory modules are usually divided into short-term memory and long-term memory. Different types of memory modules have different functions and characteristics. Through memory modules, AI Agent can better understand the current situation, generate reasonable responses, provide customized services, and continuously improve its behavior patterns by recording interaction history. Among them:
- Short-term memory is mainly used to store temporary information, such as the context of the current conversation or user instructions in a short period of time. It has the characteristics of limited capacity, fast response and time decay. It usually relies on simple data structures (such as queues or stacks) to achieve it. It can support real-time tasks, but expired content will be automatically cleaned up.
- Long-term memory is used to store persistent information, such as user preferences, historical interaction records, and knowledge bases. It has the characteristics of persistence, knowledge accumulation and personalized services, can support reasoning and question answering, and usually relies on complex technologies such as vector databases, graph databases or key-value pair storage to achieve it.
2. Existing problems
- Memory retrieval: Long-term memory is generally stored in the vector database, which is the key to personalized services. How to accurately retrieve memory data in different business scenarios and balance the relationship between retrieval efficiency and resource consumption is actually similar to RAG technology, which can integrate information from multiple dimensions. Also refer to the following figure:
- Memory compression: The amount of information accumulated by the agent is growing exponentially, while the context window and computing resources are clearly limited. Memory compression technology can significantly reduce storage and processing costs while maintaining key semantics by extracting core information and reducing redundancy.
- Intelligent forgetting: Coordinate and integrate conflicting information, and balance active memory management and passive memory acquisition. Balancing personalization and universality is another key challenge, involving the isolation and protection of user-specific memories, the abstraction and generalization of cross-user experiences, and the definition of the boundaries between privacy protection and memory sharing.
3. Related research
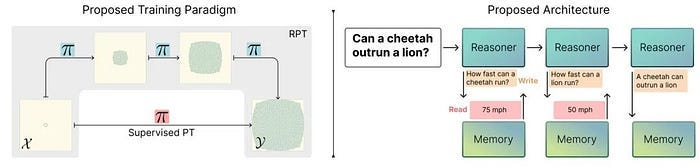
In 2025, three key directions of decoupled knowledge reasoning are proposed to help build a reasoning system that combines a well-trained retrieval system and a large external memory library to overcome the limitations of existing architectures when learning reasoning in new scenarios.
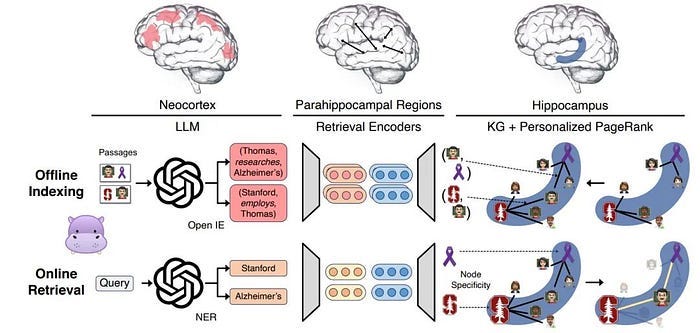
In 2024, in terms of memory compression, Stanford designed a new retrieval enhancement model called HippoRAG. Large models equipped with this “brain-like” memory system have shown amazing performance improvements in a variety of tasks that require knowledge integration. The birth of HippoRAG has opened up a new path for large models to be endowed with “brain-like” knowledge integration and long-term memory capabilities.
In 2024, AIRI faced the problem that there was no unified method to test the memory ability of an agent, and it was difficult to accurately compare the memory abilities of different agents. We simplified this problem by defining different types of memory (such as long-term memory and short-term memory) and proposed an experimental method to evaluate the memory ability of an agent.
Changes in the Agent Construction Paradigm
Since the breakthrough of LLM, we have never stopped exploring agents. We hope that the model is not just a “brain in a vat”, but can become a fully autonomous system that can run independently for a long time and complete complex tasks. In the five stages of agent development, each important progress of the agent is brought about by the iteration of model capabilities. Last December was the beginning of a paradigm change. After the release of o1, a video of the speech by OpenAI research scientist Noam Brown was leaked. He talked about workflow as all structure-based things. It has only short-term value but no long-term value. It will eventually be replaced by the inherent capabilities of the model. What we need to do is to make the model think like a human, to think freely! Coincidentally, Anthropic also published a blog on how to build an effective agent, mentioning that workflow and agent are two different architectures. Workflow is a system that orchestrates LLM and tools through predefined code paths, while agent is a system that LLM dynamically guides its own processes and tool usage, maintaining control over how they complete tasks. We do not need to build an agent system, because these abstract layers may cover up the underlying prompts and responses. It is recommended that developers start by using the LLM API directly. All of this tells us that the model’s capabilities have developed to the point where we can solve practical problems by stimulating its inherent capabilities. In fact, the reasoning model’s reasoning ability is stimulated by RL. Pre-training learns knowledge, and post-training stimulates the ability. Now, making applications is also about stimulating the model’s ability. This road ends up being end-to-end. OpenAI Deep Research is the model obtained by o3 through reinforcement fine-tuning. It is also an agent and a product.
Today, the correct way to use the reasoning model is no longer to use prompt templates. You don’t have to teach it step by step. You should describe the task and goal clearly, and let the model think and output CoT by itself. That is to say, you define the starting point and end point of the task, and let the model search for the trajectory in the middle by itself. Of course, this process is not that easy. It will fail, it will be unrealistic, it will waste a lot of tokens and fail to complete the task. This process will make you frustrated and discouraged, and then you want to use those frameworks and templates again, just like a stubborn child who can’t be taught no matter what. It’s better to just tell him the correct answer and let him memorize it. But I want to say please be more patient, don’t teach, incentivize, you can give it some guidance, or give it some rewards at the intermediate nodes, or add verifiers at the key steps, and eventually it will achieve the objective you give while maintaining considerable generalization.
Of course, some people will say that in this case, the capabilities are all model-based, and there are no barriers at the application layer. Adapting the model’s capabilities to your scenario is a barrier in itself. If you don’t believe it, try it. Now the reasoning model has such strong reasoning capabilities. You don’t use it in the chat dialog box, you directly apply it to your scenario as an agent. You don’t use workflow or structure, just release the intelligence of the model itself, and see if it can fully meet your requirements. If one day in the future a model API with PhD capabilities is readily available and cheap, do you think you have the ability to use it well? If you recruit a PhD, you will have to spend a long time getting used to him and aligning your goals, vision, and values with him before you can use his capabilities for your own benefit. After all, our work scenarios are not math problems, and there are no standard answers. How you give your guidelines and how you give your rewards are all technical work, and you have to align with it frequently to prevent it from taking shortcuts or being inconsistent with your goals. Do you think it is easy to train a backbone employee who is obedient and productive? Then why do you think it is easy to control a model?
Agent Application Scenarios
Large-model Agents have shown broad application prospects in the fields of healthcare, education, industry, financial services, and operating systems, but they also face many challenges.
In the medical field, Agents can be used for intelligent consultation, medical image analysis, personalized health management, and medical knowledge base query to improve diagnostic accuracy and optimize medical resources. However, privacy protection of medical data, regulatory compliance, and the explainability of AI diagnosis remain the main difficulties. In addition, the application of AI in the medical industry still needs to be strictly regulated to ensure its safety and reliability.
In the education field, Agents can provide intelligent tutoring, automatically correct homework, generate educational content, and assist in language learning. For example, AI-based personalized learning systems can customize learning paths according to students’ knowledge levels and improve learning efficiency. However, knowledge update issues, misleading information, and the balance between personalization and standardization remain challenges for AI education applications. Ensuring that AI can provide accurate and reliable knowledge and adapt to changing educational needs is a problem that must be solved for industry development.
Industrial field Agents can be applied to intelligent operation and maintenance, equipment predictive maintenance, intelligent manufacturing, robot control and supply chain optimization. For example, AI can analyze the operating data of industrial equipment, predict faults and optimize production processes to improve production efficiency. However, Industrial environment has high requirements for AI real-time performance, and data is often scattered in different systems, forming “data islands”. How to integrate and utilize these data has become a challenge (the big data departments of each company need to consider). In addition, when introducing AI solutions, enterprises also need to consider the balance between input costs and actual benefits to ensure the economic feasibility of AI solutions.
Financial field Agents can be used for smart investment advisors, quantitative trading, risk management, fraud detection, credit scoring and personalized financial services. AI provides investment advice and improves financial security by analyzing market data and user behavior. However, Strict supervision of the financial industry requires AI to have a high degree of transparency and explainability to ensure compliance. In addition, the financial market changes rapidly, and AI needs to have the ability to continuously learn to adapt to the changing market environment. At the same time, AI may also become a target of financial attacks, and how to prevent adversarial attacks is a key issue.
Operating System Agent can be applied to intelligent assistants, code generation, office automation and intelligent operation and maintenance. For example, intelligent assistants can help users complete tasks, search for information, manage schedules, and improve work efficiency. Code generation tools such as GitHub Copilot have also greatly improved developer productivity. However, AI assistants need to ensure privacy when collecting user data, and compatibility issues between different operating systems and software ecosystems also need to be resolved. In addition, improving the generalization ability of AI so that it can adapt to the usage habits of different users is also the key to improving user experience.
Agent Future
Menus, which has recently attracted everyone’s attention, has been promoting this concept: Less structure, more intelligence. This is a very beautiful technical philosophy. Monica’s team started with a Chrome browser plug-in. After ChatGPT became popular, it gained traffic on the web side. Later, it developed into a product matrix and made a series of shell tools. In the process, it accumulated valuable data. Later, it tried AI browsers, but gave up because it was not an AI-native interactive method. Finally, it successfully transformed into an agent product. Some people say that their products are stitched together, but I think the most important thing is that they used Qwen post-training some small models, which just made up for part of the lack of ability of the large model, making the agent’s execution effect a step up. Many teams have been using the large model + small model and multi-agent method, but the improvement is limited by simply using scaffolding or encapsulation. In the end, it was proved that the bottleneck of the agent’s ability is still the model. The Monica team’s ability to do post-training work is inseparable from the previous data accumulation. Information search, data organization, chart generation, and coding agents are all tools that have been developed before. Browse use is a function accumulated when making AI browsers, and now it has been smoothly integrated into the current products. No step is taken in vain, and every step counts, so Xiao Hong said that “the shell has its value.” They used their own small model to make up for the current defects of the LLM in tool use and action, which is equivalent to giving us part of the capabilities of the next generation of LLMs in advance, and also let us see the direction of model evolution. We have reason to believe that when the LLM further internalizes these capabilities, the agent will have a promising future. Future development direction of Agent:
1) Continuous evolution of model capabilities
Through the expansion of parameter scale and architecture optimization, large models will break through the boundaries of language understanding, logical reasoning and other capabilities. For example, in terms of task planning and tool use, the efficiency is higher; in terms of model thinking and reasoning speed, the model response will be faster. Difficulty: Distributed reasoning optimization of models with hundreds of billions of parameters reduces the hardware power consumption required by the model.
2) Multimodal fusion becomes standard
Agents in the future will integrate multimodal input and output capabilities such as text, images, and voice. For example, medical agents can simultaneously analyze CT images (visual) and medical record texts (language) to generate comprehensive diagnostic reports.
3) Formation of a collaborative ecosystem
Multi-agent systems will establish a division of labor and cooperation mechanism to achieve dynamic task allocation through a game theory framework. For example, in logistics scheduling scenarios, path planning agents, inventory management agents, etc. can form collaborative decisions based on reinforcement learning algorithms. Difficulty: Communication fault tolerance and conflict resolution during multi-agent collaboration.
4) Knowledge enhancement and cost optimization
Using RAG (retrieval enhancement generation) technology, the knowledge base can be updated without retraining. For example, financial agents can quickly respond to policy changes by accessing market data sources in real time. This requires understanding the model’s ability to integrate its own knowledge and external knowledge. Studies have shown that if the knowledge given to the model is not much different from its own knowledge, the model will prefer its own knowledge; at the same time, the model will prefer the data knowledge generated by the model.
5) Ethical security is more standardized
With the popularization of applications, problems such as data privacy and algorithm bias need to be solved. Data privacy protection can be achieved through federated learning. At present, one solution is to divide the model into blocks and place the model body remotely to reduce local resource requirements. Encryption and decryption conversion is performed on the client and model server.
Maybe someone will say, if I am not a member of the Deepseek team, I cannot train cutting-edge models, and I am not a member of the Monica or Jina team, I cannot make good products, then what should I do? Then you should digitize and online your business as much as possible, collect experience data and save it. If you believe in the power of technology and the speed of model iteration, then you should believe that they will be useful sooner or later. At that time, you only need to give rewards and leave the rest to the model. Regarding what is experience data, Richard S. Sutton, the “father of reinforcement learning” and the author of “A Bitter Lesson”, has a passage in his speech. I will post it at the end, hoping to inspire you: Data drives AI. Experience is the ultimate data. Experience comes from the ordinary operation of the AI; It is “free” data; It enables autonomous learning that scales with computation. If we can learn and plan from experience, then the whole agent will become grounded and scalable. This would be super-powerful and revolutionize AI.
